New Software Development Services At AVPreserve
May 29, 2013
One of the core concepts behind the work we do is that because the necessary tools for media collection management and preservation have been limited in scope and because the need for such tools is so urgent, it is up to us as a community to develop those tools and support others who do as well, rather than hoping the commercial sector will get around to it any time soon in the manner we require. This has been an important factor of why AVPreserve has looked to open source environments in developing utilities such as DV Analyzer, BWF MetaEdit, AVI MetaEdit, and more.
While most are aware AVPreserve has been a part of developing those desktop utilities, over the past year we have been doing a greater amount of work in the design and development of more complex, web-based systems we are using for the various needs of cataloging, managing and updating metadata, collection analysis, and digital preservation. With the collaboration of our regular development team and the designer Perry Garvin we work on all aspects of frontend and backend development, from needs assessment to wire-frames, implementation, and support. Some of the projects we have been working on are entirely built up from scratch, while others focus on implementation of existing systems or the development of micro-services that integrate with those systems to fill out their abilities for managing collections.
Some of our new systems include:
Catalyst Inventory Software:
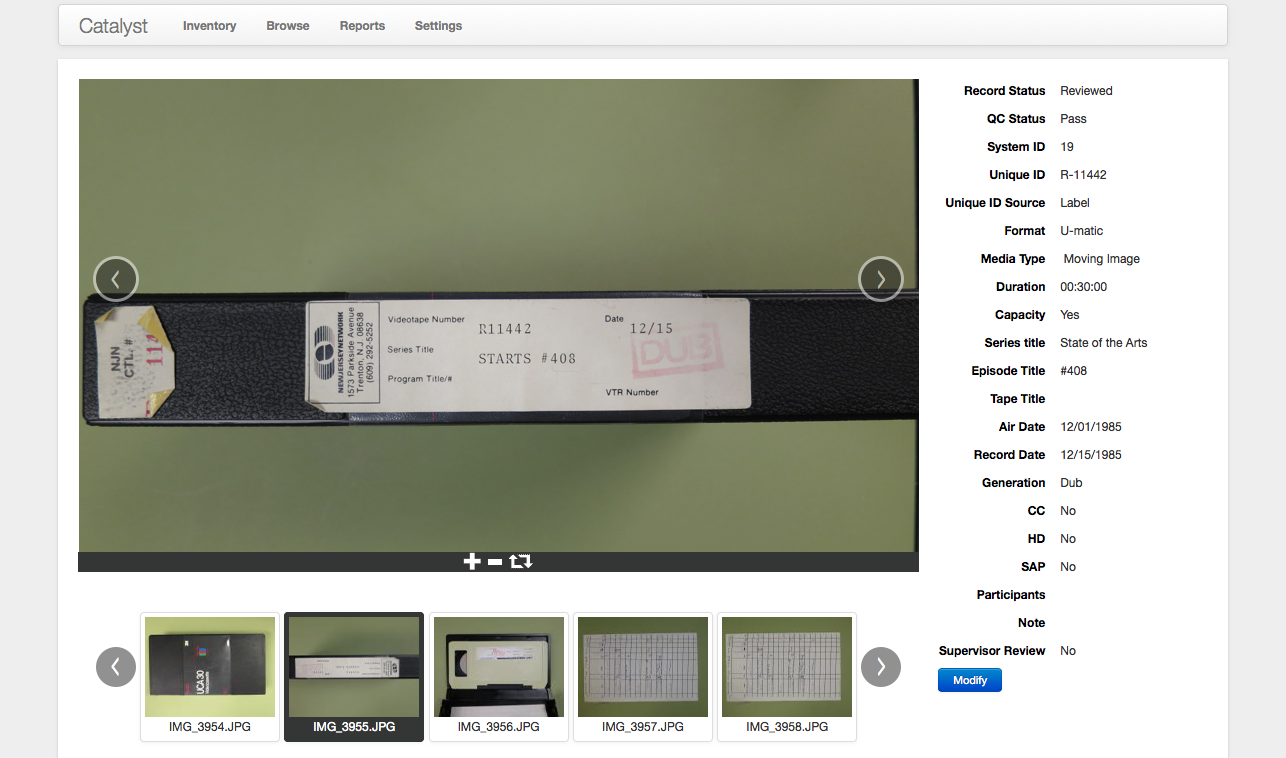
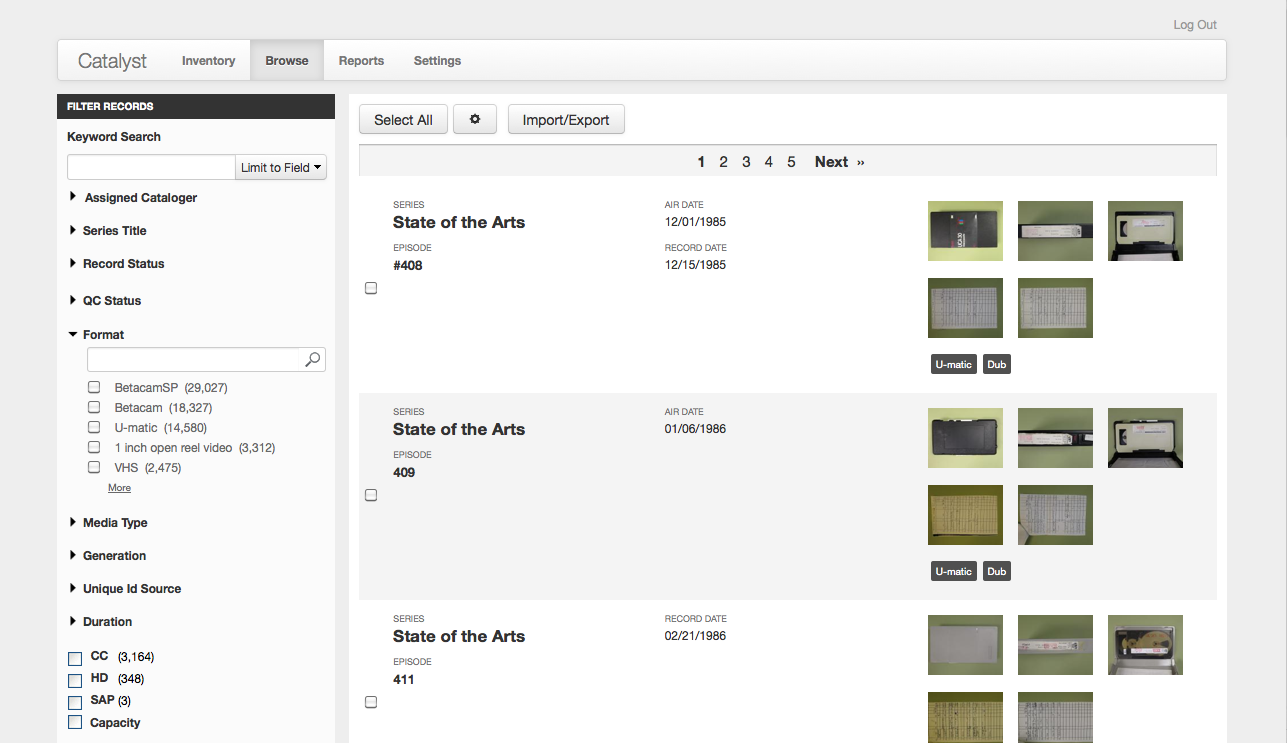
In support of our Catalyst Assessment and Inventory Services we developed this software to support greater efficiency in the creation of item-level inventories for audiovisual collections. At the core is a system for capturing images of media assets, uploading them to our Catalyst servers, and them completing the inventory record based on those images. Besides setting up a process that limits disruption onsite and moves the majority of work offsite, Catalyst also provides an experience-based minimal set of data points that are reasonably discernable from media objects without playback. This, along with the use of controlled vocabularies and some automated field completion, increases the speed of data entry and provides an organization with a useable inventory much quicker. Additionally, the images provide information that is not necessarily transcribable, that extends into deeper description beyond the scope of an inventory, or that may be meaningful for identification beyond typical means. This may include run down sheets or other paper inserts, symbols and abbreviations, or extrapolation based on format type or arrangement. Search and correct identification can be performed without pulling multiple boxes or multiple tapes, and extra information can be gleaned from the images. Catalyst was recently used to perform an item-level inventory of a collection of over 82,000 items in approximately three months.
AMS Metadata Management Tool
The AMS was built to store and manage a set of 2.5 million records consolidated from over 120 organizations. The system allows administrative level review and analytic reporting on all record sets combined, as well as locally controlled and password protected search, browse, and edit features for the data. This editing feature integrates aspects of Open Refine and Mint to perform complex data analysis quickly and easily in order to complete normalization and cleanup of records or identify gaps. Records are structured to provide description of the content on the same page along with a listing of all instantiations of that content where multiple copies exist, while also providing streaming access to proxies.
Indiana University MediaScore
AVPreserve’s development team supported Indiana University in the design and creation and MediaScore, a new survey tool used to gather inventories of collections. Within MediaScore assets are grouped at the collection or sub-collection level and then broken down by format-type with like characteristics (i.e., acetate-backed 1/4″ audio, polyester-backed 1/4″ audio, etc.), documenting such things as creation date, duration, recording standards, chemical characteristics, and damage or decay. This data is then fed into an algorithm that assigns a prioritization score to the collection based on format and condition risk factors. In this way the University is able gather the hard numbers they need for planning budgets, timelines, and storage needs for digitization their campus-wide collections while also providing a logic for where to start and how to proceed with reformatting a total collection of over 500,000 items that they feel must be addressed within the next 15 years.
**************
These are just a few of the projects we’re working on right now. We’re thrilled to be augmenting our services this way and to be able to provide fuller support to our clients, as well as to continue developing resources that will contribute to the archival field. We’re looking forward to new opportunities collaborate and provide solutions in this way.